Architecting the Package Intelligence Pipeline - Part 3
In the previous articles I laid down the requirements for a data pipeline, surveyed the available data orchestrators, and weighed them against those requirements. I consciously picked Dagster as the orchestrator for the Package Intelligence Pipeline. In this post I turn those requirements into an architecture: the asset graph, the storage, the cadences, and the gates that keep bad data out.
Mental model of the architecture
The phases of the pipeline are evident and generic. I’ll dive into each one and extract enough detail to actually wire them up.
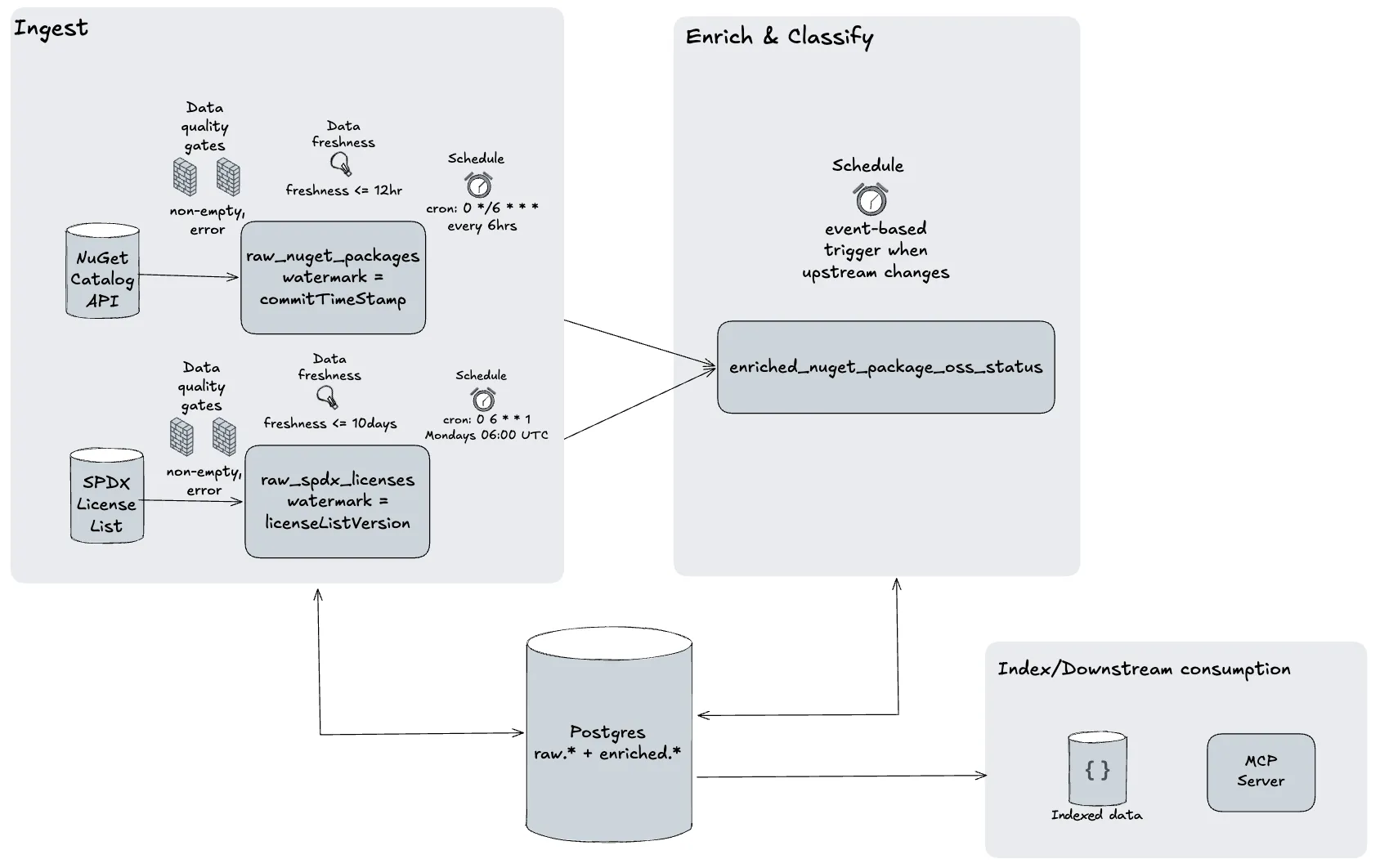
Ingest
The intent here is to fetch raw data from external sources. For this pipeline I need two kinds of data: package data from NuGet, and license type definitions. Let me go through each.
NuGet package data. NuGet exposes a public Catalog API that lets clients download package events freely. The catalog is structured as index → pages → leaves: the index lists every page ever published, each page lists ~550 leaf events, and each leaf is a single (package_id, version) event (either a publish or a delete). I can walk the index and download the data that lives on each page.
Once I hit baseline (I’ve ingested the whole registry once), I need a way to fetch only what’s changed since the last run, because re-pulling millions of leaves on every tick is a non-starter. To make incremental fetches work, I lean on commitTimeStamp. The NuGet Catalog is an append-only chronological log. Every entry, at every level of the hierarchy, carries the moment NuGet committed that catalog leaf. If I save the highest commitTimeStamp from the previous run as a watermark, the next run can walk the index, keep only the pages whose commitTimeStamp is newer than the watermark, and process just the delta. No server-side filtering, no diffing, no separate change feed: one timestamp on each entry doing the work of all three.
This is also where the plan shifted from Part 2. I expected to lean on Dagster’s partitioned assets and slice the work by day, and that capability weighed into the verdict. But the catalog turned out to be an append-only log with a natural cursor on every entry, and a single watermark gives me the same incremental guarantee with none of the partition bookkeeping. Partitions earn their keep when slices need independent retries and backfills; a forward-only log doesn’t have that shape, so the simpler primitive wins.
License type definitions. I use the SPDX license list, a public JSON document that contains every well-known license I might want to recognize. SPDX maintains a versioned list and bumps the version whenever the list changes. Building an incremental delta-fetch mechanism here doesn’t pay off: the document is small (~730 entries, a few hundred KB) and changes only when SPDX cuts a new release. It’s simpler to just rewrite the whole table whenever a new version appears upstream, and skip the work when it hasn’t.
Enrich and Classify
To recap: the intent here is to refine the raw data and devise a classifier that splits packages into open_source, proprietary, or unknown. That’s two narrowings of Part 1’s ambition, and both are deliberate. The enrichment imagined there correlated GitHub repository activity, license files, and contributor patterns; v1 narrows that to the license signals already present in the catalog data, the smallest enrichment that lets the classifier produce a defensible verdict, with the GitHub-shaped signals deferred to v2. And the output is a three-way verdict rather than the likelihood score Part 1 sketched, because a verdict with a recorded reason is easier to audit than a number. Below is the decision tree the classifier follows.
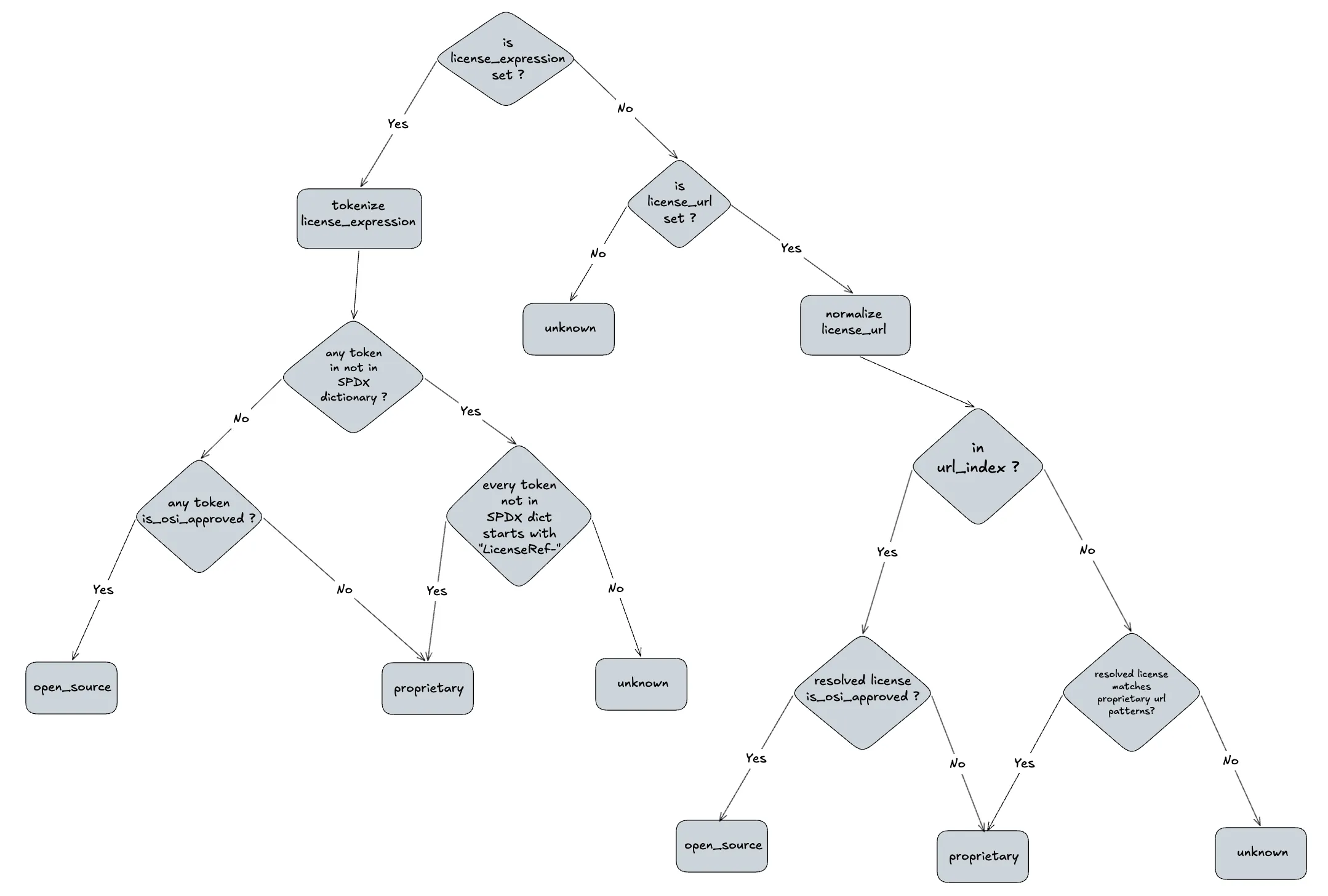
In short, I build a license-id dictionary and a normalized URL index from SPDX, tokenize the license signals on each package, and walk the decision tree to land on one of three verdicts.
With the classifier’s behavior pinned down, the enrichment phase falls out. The raw NuGet data doesn’t need much enrichment: the package’s declared license signals (licenseExpression, licenseUrl) are read directly off the row, no transformation required. The SPDX data, on the other hand, does need a bit of preparation: building the license-id dictionary and the normalized-URL index that the classifier consults. Both are trivial to construct once the SPDX rows are in Postgres. So the enrichment work is real but light: the heavy lifting lives in the classifier itself, not in any upstream transformation.
Index / Output
To recap: this phase involves indexing the classified data (using a search engine such as OpenSearch) or wrapping it in a server (for example, an MCP server) so downstream consumers can query it easily. For the pipeline I’m building here I’ll skip this step and let downstream consumers read the classified data directly from the same Postgres database that already holds the raw and enriched layers. It’s the right shape for a PoC; promoting to a dedicated index becomes interesting only when the read patterns of consumers diverge from “give me one classification by package_id”.
Data storage
With the data sources and the incremental fetch mechanism in place, I’ll turn to storage. I’ll use Postgres as the relational database for every layer. I consciously chose a relational database because the package data is relational in nature, and I’ll need the guarantees a transactional database offers: atomic per-batch upserts, foreign-key-like joins, indexes for the read patterns I expect. Reaching for something else would be less optimal for this workload. Below is the rough relational schema of the pipeline.

Highlights of the schema:
- I don’t strictly need the version-level metadata for the classifier to work, because the declared license rarely changes across versions of a package. But the NuGet Catalog API hands me events at version grain (one leaf per (
package_id,version) publish), so I have to land them somewhere. Storing the version metadata alongside the package row is cheaper than discarding it on ingest and re-fetching later. - I keep the raw response body from the NuGet Catalog API in a JSONB column on each row. This is the escape hatch: if I later need to surface a field I didn’t pre-columnize, I can query it out of the JSON instead of triggering a full re-walk of the catalog over the network. That decision already paid for itself once, when the classifier needed
licenseUrlafter the fact and I didn’t have to refetch anything.
Schedules
The schedule attached to each dataset depends on a couple of factors. NuGet package data has higher day-to-day churn because it’s a busy public registry: new versions get published continuously. The SPDX license list, by contrast, changes only when SPDX cuts a new release, which is roughly quarterly. Both of these are time-based by nature, so I attach a cron schedule to each.
Part 1 hoped to watch NuGet’s feed of updates instead of polling on a schedule and hoping. It turns out the catalog is that feed, and it’s pull-based: there is no push channel to subscribe to, so “watching the feed” degenerates into polling it on a cadence. The event-driven part of the plan isn’t dead, though; it survives one hop downstream, in how the classifier gets triggered.
I picked a 6-hour cadence for the NuGet ingest (four times a day, every day) and a weekly cadence for the SPDX sync (Mondays 06:00 UTC). Six hours keeps the worst-case ingest lag below half a day without flooding NuGet with no-op requests, and weekly is generous slack on top of SPDX’s actual release cadence: the worker no-ops cheaply on an unchanged version anyway.
For the enrichment and classification asset, attaching a cron schedule would be a workaround, not a solution. The classifier depends on its upstreams being ready, and a fixed time offset would be guessing when “ready” happens. I’ll trigger the enrichment on an event instead: whenever either upstream finishes materializing, queue a classifier run. The dependency graph drives the cadence, so I don’t have to keep a third schedule in sync with the first two. Both schedules ship stopped by default, so nothing fires the moment the repo is deployed; an operator flips them on once during commissioning.
Data quality gates
With schedules attached to assets, the surface area for bad data to slip in widens. Adding multi-layer quality checks is no longer optional. The following table covers the checks I’m adding, from the cheapest-and-always-on at the bottom to the most visible at the top.
| Layer | Where | What it catches | Cost | Visibility |
|---|---|---|---|---|
| Postgres constraints | DDL | invalid values, duplicate keys, nulls | microseconds per write | crash on insert |
| Pydantic validation | sync workers | upstream schema drift | one parse per row | crash + traceback |
| Runtime guards | worker code | missing prerequisites (empty SPDX, etc.) | one if-check at boot | crash + clear error |
| Dagster asset checks | asset_checks.py | post-materialization quality (empty table, missing licenses, regression alarms) | one SQL count per run | UI badge; blocking checks gate downstream |
Each layer answers a different question. Postgres constraints ask “is this value valid?” Pydantic asks “does the upstream payload match the shape I expect?” Runtime guards ask “do I have what I need to run?” Asset checks ask “does the data I just wrote pass my quality bar?” The two ERROR-severity asset checks (raw_nuget_packages_nonempty and raw_spdx_licenses_osi_floor) are blocking, so a failure on the raw layer stops the eager classifier from materializing on bad upstream data. That’s the “stop the cascade” mechanism the requirements list called for.
Data freshness policies
For operational visibility, I’ll add data freshness checks that warn when an asset goes stale relative to its expected cadence. The table below explains the thresholds and the rationale behind each.
| Asset | Cadence | Threshold | Rationale |
|---|---|---|---|
raw_nuget_packages (WARN) | nuget_incremental schedule every 6h + nuget_staleness sensor as fallback | 12h | 2× schedule cadence; one missed tick is noise, a second consecutive miss trips the warning |
raw_spdx_licenses (WARN) | spdx_weekly schedule (Mondays 06:00 UTC) | 10d | Weekly schedule + 3 days slack |
enriched_nuget_package_oss_status (WARN) | AutomationCondition.eager(); fires when either upstream materializes | 24h | NuGet’s 12h SLA + classifier latency + eager-sensor tick budget |
The pattern across all three: each freshness threshold is the expected cadence plus enough slack to absorb one missed run before the asset flips to stale in the UI. That matches the typical “a transient failure recovered on the next tick” pattern and stops the freshness signal from page-screaming on every minor hiccup. All three are WARN, not ERROR, and none are blocking: stale data is still queryable, the check just surfaces “this hasn’t refreshed in a while” on the asset’s UI card.
What’s next
That covers the plan: the asset graph, the data storage, the cadences, the quality gates, and the freshness policies. Each one was a deliberate decision against the requirements I started with, and each one has a clean line back to something the orchestrator either does for me or stays out of my way for. The next post is the wiring, how each of these decisions becomes actual Dagster assets, Postgres tables, and Python code in the pipeline repo.